

Large Language Models have revolutionized natural language processing, demonstrating impressive capabilities in text generation, translation, and question answering. However, their reliance on pre-existing knowledge limits their ability to provide accurate and up to date information, especially when dealing with specialized domains or rapidly evolving data. Retrieval-Augmented Generation (RAG) addresses this limitation by combining the power of LLMs with external knowledge sources. Instead of solely relying on their internal parameters, RAG models retrieve relevant information from a knowledge base and incorporate it into the generation process, leading to more informed and reliable responses. This post explores several RAG architectures, highlighting their strengths and weaknesses.
We’ll cover the following approaches:
- Naive RAG: The simplest implementation, providing a foundational understanding of the RAG pipeline.
- Graph RAG: Leverages knowledge graphs for more structured and relational information retrieval.
- Hybrid RAG: Combines different retrieval strategies for improved robustness and recall.
- Memory-Augmented RAG: Integrates a dynamic memory component to personalize responses and adapt to evolving information.|
Let’s begin with the simplest, yet often surprisingly effective approach: Naive RAG.
Naive RAG: The Foundation of Knowledge-Augmented LLMs
A Naive RAG is the most basic implementation of RAG, designed to enhance language model responses by retrieving relevant data from an external knowledge base. It’s considered “naive” because it follows a straightforward retrieval-then-generation pipeline without sophisticated optimizations like query reformulation, multi-hop reasoning, or advanced reranking mechanisms. The retrieval component typically utilizes a vector database like FAISS or Pinecone, where documents are stored as vector embeddings for efficient similarity search. When a user submits a query, the system transforms it into an embedding and retrieves the top-K most relevant documents based on cosine similarity or another distance metric. These documents provide additional context to the generative model.
Press enter or click to view image in full size
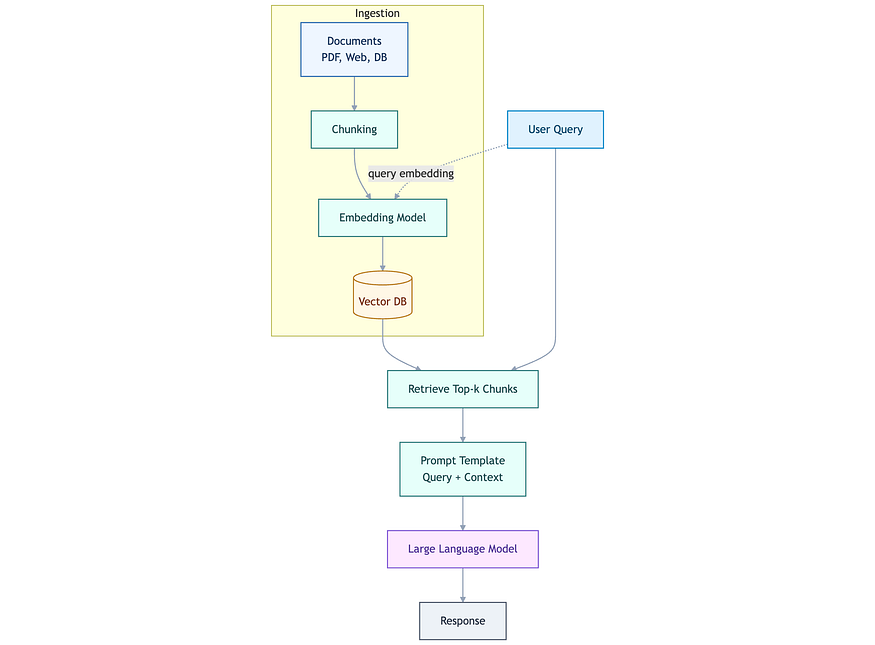
Naive RAG pipeline
Naive RAG offers the most straightforward and accessible way to connect LLMs to external resources. It forgoes dynamic memory and multi-hop logic in favor of fast, targeted lookups and generation. Its low cost and ease of implementation make it an excellent starting point for more advanced RAG architectures. In fact, for many problems, Naive RAG proves to be “good enough.”
Data Collection and Retrieval
The foundation of any RAG system is its knowledge base; this data can range from web pages and PDFs to documentation and images. The more relevant and cleaner the data, the better the results. RAG systems typically split documents into chunks to enable more precise retrieval. Chunk size is a hyperparameter that needs to be experimented with based on the specific problem. Some common chunking methods include:
- Sentence-level chunking: Offers high granularity and works well when questions are particular (e.g., fact lookup, short definitions). It’s often used in chatbots or compliance queries.
- Paragraph-level chunking: Preserves more local context and is suitable for summarization or questions about flow, tone, and logic. It’s often used in Document Q&A and product manuals.
- Section-level chunking: Uses larger units and works well when full context is needed to avoid misinterpretation. It’s often used in legal, finance, and academic analysis.
Embedding models transform the text into numerical representations that capture semantic meaning. This is crucial for both query and document processing. Embedding converts each chunk into a high-dimensional vector (ranging from 768 to 1536 dimensions) representing its semantic content. The quality of the embedding model significantly impacts retrieval performance, as it determines how effectively semantic similarity can be measured.
Pros and Cons of Naive RAG
Like any approach, Naive RAG has its strengths and weaknesses. Understanding these trade-offs is crucial for determining if it’s the right solution for your specific needs.
Pros:
- Speed of implementation: Quick to set up using widely available tools.
- Ease of integration: Works with commercial LLM APIs and common retrieval systems like FAISS or OpenSearch.
- Low operational complexity: Minimal configuration required.
- Cost-effective: Utilizes existing tools with minimal overhead.
- Ideal for prototyping: Good starting point before committing to advanced pipelines.
- Effective for static, well-structured corpora: Works well when information changes infrequently.
- Strong for FAQs and knowledge bases: Performs well with straightforward lookups.
- Reduces human support workload: Automates common information retrieval tasks.
- Improves response consistency: Provides standardized answers to common queries.
- Enables natural language enterprise search: Users can query in plain language.
- Supports educational applications: Can generate explanations and summaries.
Cons:
- Loose coupling between retrieval and generation: No deeper reasoning or iterative refinement in document selection.
- Inconsistent relevance: Retrieved chunks often vary in relevance quality.
- Context pollution: Irrelevant or redundant information can contaminate the prompt context.
- Token limit constraints: Retrieved content often hits model context limits.
- Poor prioritization: LLM may fail to focus on the most critical information.
- No feedback loops: Cannot adapt retrieval based on generation progress.
- Limited reasoning across documents: Cannot effectively chain information for multi-hop queries.
- Verification challenges: Cannot verify factual claims independently.
- Insufficient for high-stakes domains: Not reliable enough for legal, medical, or financial analysis.
- Difficult evaluation: Hard to determine if errors stem from retrieval or generation.
- Limited transparency: Hampers debugging and performance enhancement efforts.
In the next article, we will explore other advance techniques and below is the experiment with naive RAG on TriviaQA dataset.
Example of Naive RAG on the TriviaQA Dataset
<mark>TriviaQA</mark> <mark> is a real question-answer pair dataset available on </mark> <mark>Hugging Face</mark><mark>.</mark>
We will be using all-MiniLM-L6-v2 as the embedding model. The all-MiniLM-L6-v2 model is a compact and efficient sentence transformer developed by the SentenceTransformers team. With only 33 million parameters, producing 384-dimensional embeddings, this model balances speed, memory usage, and semantic understanding. It was trained using contrastive learning on a large collection of sentence pairs to effectively capture semantic similarity, making it suitable for a wide range of natural language understanding tasks. The model is widely available through Hugging Face and integrates easily with standard Python frameworks.
import os, re, itertools, random
from collections import Counter
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from datasets import load_dataset
TARGET = 50 # how many examples with contexts you want
ROW_CAP = 2000 # max rows to scan from the stream before giving up
PER_EXAMPLE_CAP = 8 # max contexts per question
TOP_K = 4
EVAL_N = 15
def gold_answers(row):
ans = row.get("answer")
if isinstance(ans, dict):
vals = []
if ans.get("value"): vals.append(ans["value"])
if ans.get("aliases"): vals.extend(ans["aliases"])
return list(dict.fromkeys(vals))
if isinstance(ans, str): return [ans]
return []
def extract_contexts_from_search(row, cap=PER_EXAMPLE_CAP):
blobs = []
sr = row.get("search_results")
if isinstance(sr, list):
for r in sr:
for k in ("search_context", "description", "title", "snippet"):
t = r.get(k)
if t: blobs.append(str(t))
if len(blobs) >= cap: break
elif isinstance(sr, dict):
# best-effort: pull parallel arrays if present
for key in ("search_context", "description", "title", "snippet"):
v = sr.get(key)
if isinstance(v, list):
for item in v:
if item: blobs.append(str(item))
if len(blobs) >= cap: break
elif isinstance(v, str):
blobs.append(v)
if len(blobs) >= cap: break
out, seen = [], set()
for b in blobs:
t = " ".join(b.split())
if t and t not in seen:
out.append(t); seen.add(t)
return out[:cap]
def stream_collect(dataset, config, split, target=TARGET, row_cap=ROW_CAP):
print(f"Trying {dataset}/{config} [{split}] (streaming)…")
ds_iter = load_dataset(dataset, config, split=split, streaming=True)
examples, scanned = [], 0
for r in ds_iter:
scanned += 1
q = (r.get("question") or "").strip()
if not q:
if scanned >= row_cap: break
continue
docs = extract_contexts_from_search(r, cap=PER_EXAMPLE_CAP)
if docs:
examples.append({"question": q, "golds": gold_answers(r), "docs": docs})
if len(examples) >= target:
break
if scanned >= row_cap:
break
print(f"Collected {len(examples)} good examples after scanning {scanned} rows.")
return examples
order = [
("mandarjoshi/trivia_qa", "rc", "train"),
("mandarjoshi/trivia_qa", "rc", "validation"),
("mandarjoshi/trivia_qa", "unfiltered.nocontext", "train"),
]
examples = []
for ds, cfg, split in order:
examples = stream_collect(ds, cfg, split)
if examples: break
if not examples:
raise SystemExit("Still no contexts. Increase ROW_CAP (e.g., 5000) or switch to SQuAD v2 for a guaranteed context field.")
# ---- embed + index in-memory ----
from sentence_transformers import SentenceTransformer
embed = SentenceTransformer("all-MiniLM-L6-v2")
flat_docs, flat_meta = [], []
for i, ex in enumerate(examples):
for j, d in enumerate(ex["docs"]):
flat_docs.append(d)
flat_meta.append({"ex_idx": i, "doc_idx": j})
def batched(xs, n=64):
for i in range(0, len(xs), n):
yield xs[i:i+n]
doc_vecs = []
for batch in batched(flat_docs, 64):
doc_vecs.extend(embed.encode(batch, show_progress_bar=False).tolist())
import chromadb
client = chromadb.EphemeralClient()
col = client.get_or_create_collection("triviaqa_naive_rag_mem")
ids = [f"{m['ex_idx']}-{m['doc_idx']}" for m in flat_meta]
col.add(ids=ids, documents=flat_docs, embeddings=doc_vecs, metadatas=flat_meta)
# ---- eval ----
def norm(s: str) -> str:
s = s.lower()
s = re.sub(r"[^\w\s]", " ", s)
s = re.sub(r"\b(a|an|the)\b", " ", s)
return " ".join(s.split())
def exact_match(pred, golds):
p = norm(pred)
return max(1 if p == norm(g) else 0 for g in golds) if golds else 0
from collections import Counter
def f1(pred, golds):
pt = norm(pred).split()
best = 0.0
for g in golds:
gt = norm(g).split()
common = Counter(pt) & Counter(gt)
n = sum(common.values())
if n == 0: continue
prec = n / max(1, len(pt)); rec = n / max(1, len(gt))
best = max(best, (2*prec*rec)/(prec+rec) if (prec+rec) else 0.0)
return best
from langchain_openai import ChatOpenAI
from langchain import PromptTemplate, LLMChain
llm = ChatOpenAI(model="gpt-4o-mini", api_key="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")
prompt = PromptTemplate.from_template(
"Answer using ONLY the context. If not present, say 'Unknown'.\n\n"
"# Question\n{question}\n\n# Context\n{context}\n\n# Final Answer\n"
)
random.seed(0)
n_eval = min(EVAL_N, len(examples))
picked = random.sample(range(len(examples)), n_eval)
em_sum = f1_sum = 0.0
for idx in picked:
ex = examples[idx]
q, golds = ex["question"], ex["golds"]
qv = embed.encode([q]).tolist()[0]
res = col.query(query_embeddings=[qv], n_results=TOP_K, include=["documents"])
ctx = "\n\n---\n\n".join(res["documents"][0])
pred = LLMChain(llm=llm, prompt=prompt).run({"question": q, "context": ctx}).strip()
em_sum += exact_match(pred, golds)
f1_sum += f1(pred, golds)
print("\nQ:", q)
print("Pred:", pred)
print("Gold:", golds[:5])
print(f"\n=== Streamed Naive RAG (TriviaQA nocontext) ===")
print(f"Examples: {len(examples)} | Eval: {n_eval} | TopK: {TOP_K}")
print(f"EM: {em_sum/n_eval:.3f} | F1: {f1_sum/n_eval:.3f}")
Result
Q: In which branch of the arts does Allegra Kent work?
Pred: Dance and Children's Literature
Gold: ['Ballet', 'Ballet competitions', 'Ballet schools', 'Balet, India', 'Balletti']
Q: The US signed a treaty with which country to allow the construction of the Panama Canal?
Pred: Panama
Gold: ['Columbia', 'Columbia (municipality)', 'Columbia (song)', 'Columbia automobile', 'Columbia (yacht)']
Q: Banting and Best pioneered the use of what?
Pred: Banting and Best pioneered the use of insulin.
Gold: ['Insulin', 'Insulin antagonists', 'Human Mixtard', 'Insulin recombinant purified human', 'INS (gene)']
Q: In which decade did Billboard magazine first publish and American hit chart?
Pred: 1930s
Gold: ['30s', "30's", '30’s', '30s AD', '30-39']
Q: Which prince is Queen Elizabeth II's youngest son?
Pred: Prince Edward, the Queen Elizabeth II's youngest son.
Gold: ['Edward', 'Eadweard']
Q: Who was the first woman to make a solo flight across the Atlantic?
Pred: Amelia Earhart
Gold: ['Amelia Earhart', 'Amelia airheart', 'Amelia Airhardt', 'Disappearance of Amelia Earhart', 'Amelia Airhart']
Q: Ezzard Charles was a world champion in which sport?
Pred: Boxing
Gold: ['Boxing', 'Prize fight', 'Prize fighting', 'Fistfighting', 'Corner men']
Q: Who had a 70s No 1 hit with Billy, Don't Be A Hero?
Pred: Bo Donaldson and the Heywoods
Gold: ['Bo Donaldson & The Heywoods', 'Bo donaldson and the heywoods', 'Bo Donaldson and the Heywoods', 'Bo Donaldson and The Heywoods', 'The Heywoods']
Q: Who was the only Spice Girl not to have a middle name?
Pred: Unknown.
Gold: ['Posh Spice', 'My Love Is For Real (Victoria Beckham song', 'Romeo James Beckham', 'Harper Seven Beckham', 'Victoria addams']
Q: Which is the largest of the Japanese Volcano Islands?
Pred: Iwo Jima
Gold: ['Iwo Jima', 'Mount Surabachi', 'Iō-tō', 'Iwō Tō', 'Iwo-Jima']
Q: Who wrote the novel Evening Class?
Pred: Maeve Binchy
Gold: ['Maeve Binchy']
Q: Which George invented the Kodak roll-film camera?
Pred: George Eastman
Gold: ['Eastman', 'Eastman (disambiguation)']
Q: Which country is Europe's largest silk producer?
Pred: Unknown
Gold: ['Italy', 'Environment of Italy', 'Italiën', 'Subdivisions of Italy', 'Republic of Italy']
Q: Stapleton international airport is in which US state?
Pred: Colorado
Gold: ['Colorado', 'Colorado (State)', 'Colorful Colorado', 'Special districts of Colorado', 'Insignia of the State of Colorado']
Q: Which William wrote the novel Lord Of The Flies?
Pred: William Golding
Gold: ['Golding', 'Golding (surname)', 'Golding (disambiguation)']
=== Streamed Naive RAG (TriviaQA nocontext) ===
Examples: 50 | Eval: 15 | TopK: 4
EM: 0.400 | F1: 0.539
Conclusion:
- Successful Retrieval: For questions like “Who was the first woman to make a solo flight across the Atlantic?” (Amelia Earhart) and “Ezzard Charles was a world champion in which sport?” (Boxing), the system successfully retrieved the correct context and extracted the right answer.
- Graceful Failure: The model correctly answered “Unknown” for the Spice Girls and Italy silk producer questions. This is a sign of success, as it shows the model is obeying the prompt and not hallucinating an answer when the context is insufficient.
- Retrieval Failure: The question about the Panama Canal treaty is a classic RAG failure. The system likely retrieved documents about the modern Panama Canal, leading it to answer “Panama,” whereas the historical treaty was signed with “Columbia” (from which Panama later seceded).
- Verbosity vs. Precision: For questions about Prince Edward and Banting/Best, the model provided a correct, full-sentence answer. However, this verbosity caused it to fail the strict “Exact Match” metric, which was looking for a shorter, more precise term (“Edward”, “Insulin”). This is a common behavior that can be mitigated by refining the prompt to ask for a more concise answer.


